Blog System/5
My newsletter on operating systems, build systems, programming languages, software engineering, and my own software projects. Specifics include my learnings from my time at Google, Microsoft, and Snowflake, and my work on projects such as FreeBSD, Linux, Rust, Bazel and EndBASIC.
EndTRACKER
A collection of web services to supercharge your static websites. Offers privacy-respecting analytics, comments, page voting, and email subscriptions. Use the provided JavaScript client or build your own via the REST interface.
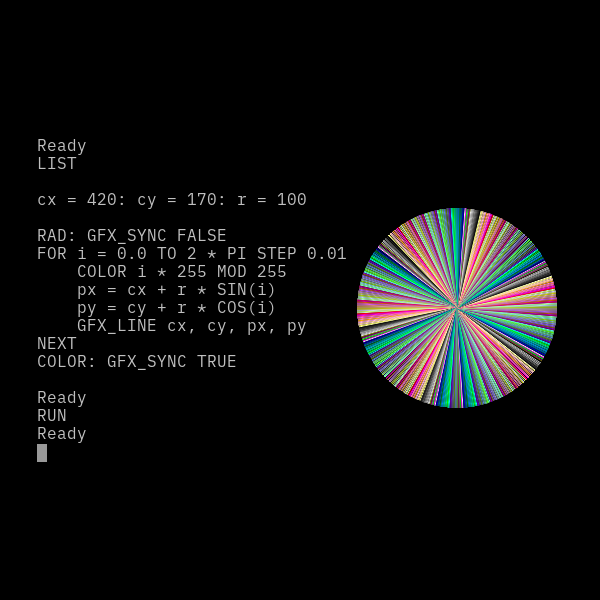
EndBASIC
A retro-looking BASIC interpreter made for the web. Simplifies the coding experience for learning purposes by mimicking the computers of the 80s. Sports a DOS-like interface, built-in editor, graphics and GPIO support for immediate feedback, and cloud storage drivers for file sharing. Runs on your browser but also on your favorite desktop OS.

... and much, much more
The above is just a teeny-tiny highlight of my "work outside of work". My newsletter/blog has been alive for almost 20 years and I've been writing code for longer than that. So peek around; you might find something else interesting here.
